

이번 프로젝트에서는 aws rds 를 구현해보고 싶어서 내가 맡게 되었다.
채용 공고들을 보다가 redis 구현 경험 이 조건인게 많아서 이기도 했고
redis 를 다른 프로젝트를 보면 사용한 게 많았는데 사용하는 이유가 궁금해서
이번 기회에 프로젝트에 적용해보고자 먼저 공부를 위해 강의를 구매했다.
Redis 란
Redis는 데이터 처리 속도가 엄청 빠른 NoSQL 형태 데이터베이스이다.
NoSQL 데이터베이스는
Key-Value 형태로 저장하는 데이터베이스이다.

데이터 처리 속도가 엄청 빠른 이유는 인메모리(in-memory) 에 모든 데이터를 저장하기 때문이다. 즉, 메모리 안에 데이터를 저장하기 때문에 디스크에 데이터를 저장하는 RDBMS의 데이터베이스인 MYSQL 과 같은 것들보다 처리 속도가 빠르다.
redis는 현업에서 캐싱 (데이터 조회 성능 향상) 에 쓰인다.
Redis 설치하기
Redis 를 설치하기 위해 아래 링크를 통해 설치했고
https://ittrue.tistory.com/318
[Redis] 윈도우10 환경에서 레디스 설치하기
Redis 설치 프로그램 다운로드 아래 링크에 접속하여 msi 확장자의 Redis 설치 프로그램을 다운로드한다. https://github.com/microsoftarchive/redis/releases Releases · microsoftarchive/redis Redis is an in-memory database that
ittrue.tistory.com
설치후, redis-cli.exe 를 실행하여 아래와 같이 잘 연결된 걸 확인할 수 있었다.

비밀번호는 링크를 따라 설정했다.
Redis 기본 명령어 익히기
- 데이터 (key, value) 저장하기
- 네이밍 컨벤션: 콜론 : 을 활용해 계층적으로 의미를 구분해서 사용한다.
# set [key 이름] [value]
set jaeseong:name "jaeseong park"
set jaeseong:hobby soccer- 데이터 조회하기 (key로 value값 조회하기)
#get [key이름]
get jaeseong:name
get jaeseong:hobby
get pjs:name #없는 데이터를 조회할 경우 (nil)이라고 출력- 저장된 모든 key 조회하기
keys *- 데이터 삭제하기(key로 데이터 삭제하기)
#del [key 이름]
del jaeseong:hobby
get jaeseong:hobby #삭제여부 확인- redis의 특징인 데이터 저장시 만료 시간 (TTL = Time To Live) 정하기
- redis의 특성상 메모리 공간이 한정되어 있기 때문에 모든 데이터를 redis에 저장할 수 없다. 따라서 만료 시간을 정해두어 자주 사용되는 데이터만 redis에 저장해서 쓰는 방식을 활용한다.
#set [key 이름] [value] ex [만료 시간(초)]
set jaeseong:pet dog ex 30- 만료시간 확인
# ttl [key 이름]
# 만료시간이 몇 초 남았는지 반환
# 키가 없는 경우 -2 반환
# 키는 존재하지만 만료 시간이 설정되지 않거나 만료시간이 지난 경우 -1 반환
ttl jaeseong:pet
ttl jseseong:name- 모든 데이터 삭제
flushall캐시 (Cache) , 캐싱 (Caching)
캐시란 원본 저장소보다 빠르게 가져올 수 있는 임시 데이터 저장소 이다
캐싱 이란 캐시 에 접근해서 데이터를 빠르게 가져오는 방식이다.

데이터를 캐싱할 때는 2가지 전략을 쓸 수 있다.
Cache Aside
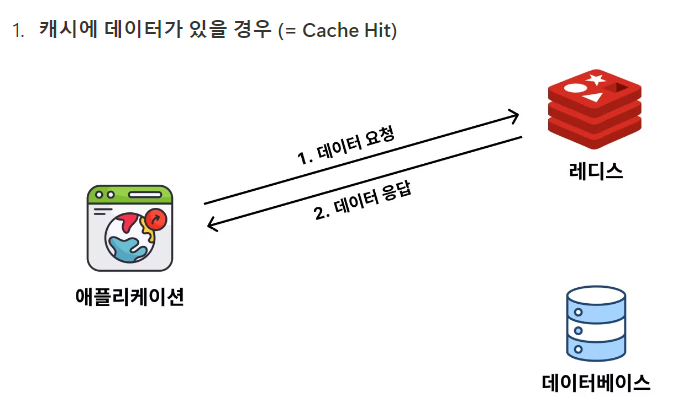

캐시에서 데이터를 확인하고, 없다면 DB를 통해 조회해오는 방식이다.
Write Around
Cache Aside 전략이 데이터를 어떻게 조회할 지에 대한 전략이었다면, Write Around 전략은 데이터를 어떻게 쓸 지(저장, 수정, 삭제)에 대한 전략이다.
Write Around 전략은 생각보다 너무 간단하다. 데이터를 저장할 때는 레디스에 저장하지 않고 데이터베이스에만 저장하는 방식이다. 그러다 데이터를 조회할 때 레디스에 데이터가 없으면 데이터베이스로부터 데이터를 조회해와서 레디스에 저장시켜주는 방식이다.
위 두 캐싱 방법의 한계점
두 방법을 같이 썼을 때 한계점 중 하나는
레디스에 저장한 데이터와 데이터베이스에 저장한 데이터가 같지 않을 수 있다는 점이다.
즉 일관성을 보장할 수 없다.
그리고 캐시에 저장할 수 있는 공간이 비교적 작아 일반 DB에 비해 많은 양의 데이터를 저장할 수 없다.
이 한계를 극복하기 위해 TTL 만료시간을 정해두어
일정 시간이 지나면 캐시에서 데이터가 삭제되고
사용자가 삭제된 데이터를 조회하려 할때 캐시에는 없으므로 db에서 조회하여 다시 캐시에 저장해
값을 갱신시킨다.
완벽히 두 한계점을 극복할 수 있는 것은 아니지만
TTL 덕에 기존 한계점을 어느정도는 커버할 수 있을 것이다.
Redis 를 Spring Boot 프로젝트에 추가하기
1. redis 의존성 추가
dependencies {
...
implementation 'org.springframework.boot:spring-boot-starter-data-redis'
}2. application.yml 파일 수정
# local 환경
spring:
profiles:
default: local
datasource:
url: jdbc:mysql://localhost:3306/mydb
username: root
password: password
driver-class-name: com.mysql.cj.jdbc.Driver
jpa:
hibernate:
ddl-auto: update
show-sql: true
data:
redis:
host: localhost
port: 6379
logging:
level:
org.springframework.cache: trace # Redis 사용에 대한 로그가 조회되도록 설정3. redis 설정 추가하기
config/RedisConfig
@Configuration
public class RedisConfig {
@Value("${spring.data.redis.host}")
private String host;
@Value("${spring.data.redis.port}")
private int port;
@Bean
public LettuceConnectionFactory redisConnectionFactory() {
// Lettuce라는 라이브러리를 활용해 Redis 연결을 관리하는 객체를 생성하고
// Redis 서버에 대한 정보(host, port)를 설정한다.
return new LettuceConnectionFactory(new RedisStandaloneConfiguration(host, port));
}
}config/RedisCacheConfig
이 파일을 통해서 redis에 저장할 key, value 값을 string, json 으로 직렬화해서 저장한다.
또한 만료기간도 설정해서 반환한다
4. BoardService
@Cacheable 어노테이션을 붙이면 Cache Aside 전략으로 캐싱이 적용된다.
- @Cacheable 어노테이션을 import 할때
import org.springframework.cache.annotation.Cacheable위에 거로 했어야했는데, import jakarta. 그런거로 되어서 이걸 찾느라 애를 먹었다.
테스트 해보기 및 캐싱 정상 여부 확인

위와 같이 redis 가 사용되는게 보여지고
캐싱을 하지 않을때와 할때 속도차이를 비교해보면
캐싱을 사용하지 않을 때 2.82s 가 걸리고,

캐싱을 사용할 때에는 두번째 조회부터는 76ms 로 조회 시간이 더 빨라진 것을 볼 수 있다.
