

안녕하세요. 코딩신생아 입니다. 공부를 통해 배운 내용을 작성하고 있습니다.
이번 포스팅에서는 mysql 인덱싱 구축 개요 및 해당 부분에 대한 개념을 정리하려 합니다.
목차
01. mysql 인덱싱을 구축하게된 상황
02. mysql 인덱싱 외의 다른 선택지
03. 인덱싱과 n-gram 파서
04. Like 문을 이용한 조회와 인덱싱을 이용한 조회 실행 속도 비교(sql 단일 쿼리)
05. 실행 속도 비교(n-grinder)
06. 인덱싱 조회를 구축하면서 느낀점
01. mysql 인덱싱을 구축하게된 상황
빌딩 명칭과 카테고리를 검색할때 사용자가 검색어를 모두 입력하지 않아도 지금까지 입력한 텍스트만으로 검색결과로 가능한 선택지를 보여주는 검색엔진을 만들면 어떨까에서 시작되었다. (아래 그림 참고)
기존 빌딩,카테고리 데이터는 mysql에 저장되어 20개 내외 정도의 데이터이다. 쿼리 상 Like를 사용하여 간단하게 만들 수 있지만, 어떤 경우에는 full scan 이 발생하여 성능 저하를 초래할 수 있다.
01-1. 인덱스란
인덱스는 데이터베이스에서 데이터를 조회할 때 빠르게 추출할 수 있도록 도와주는 '데이터베이스 개체'이다. 인덱스는 모두 균형 트리(B-tree)로 만들어지는데 데이터가 저장되는 공간을 '노드'라고 한다. 노드의 위치에 따라 루트노드, 중간노드, 리프 노드로 구성되고, mysql에서는 이러한 노드들을 '페이지'라고 부른다.
균형 트리가 검색할때 뛰어난 성능을 발휘하는 이유는 full scan에 소요되는 시간보다 더 빠르게 진행되기 때문이다. 루트 페이지에서 검색할 데이터가 몇 번 페이지에 있는지 탐색하고 해당 페이지를 확인하여 데이터를 추출하게 된다.
인덱스에는 두 가지 종류가 있다.
- 클러스터형 인덱스(Clustered Index)
테이블당 1개의 인덱스가 존재하고, 실제 데이터가 인덱스가 걸린 기본키를 기준으로 정렬된다.
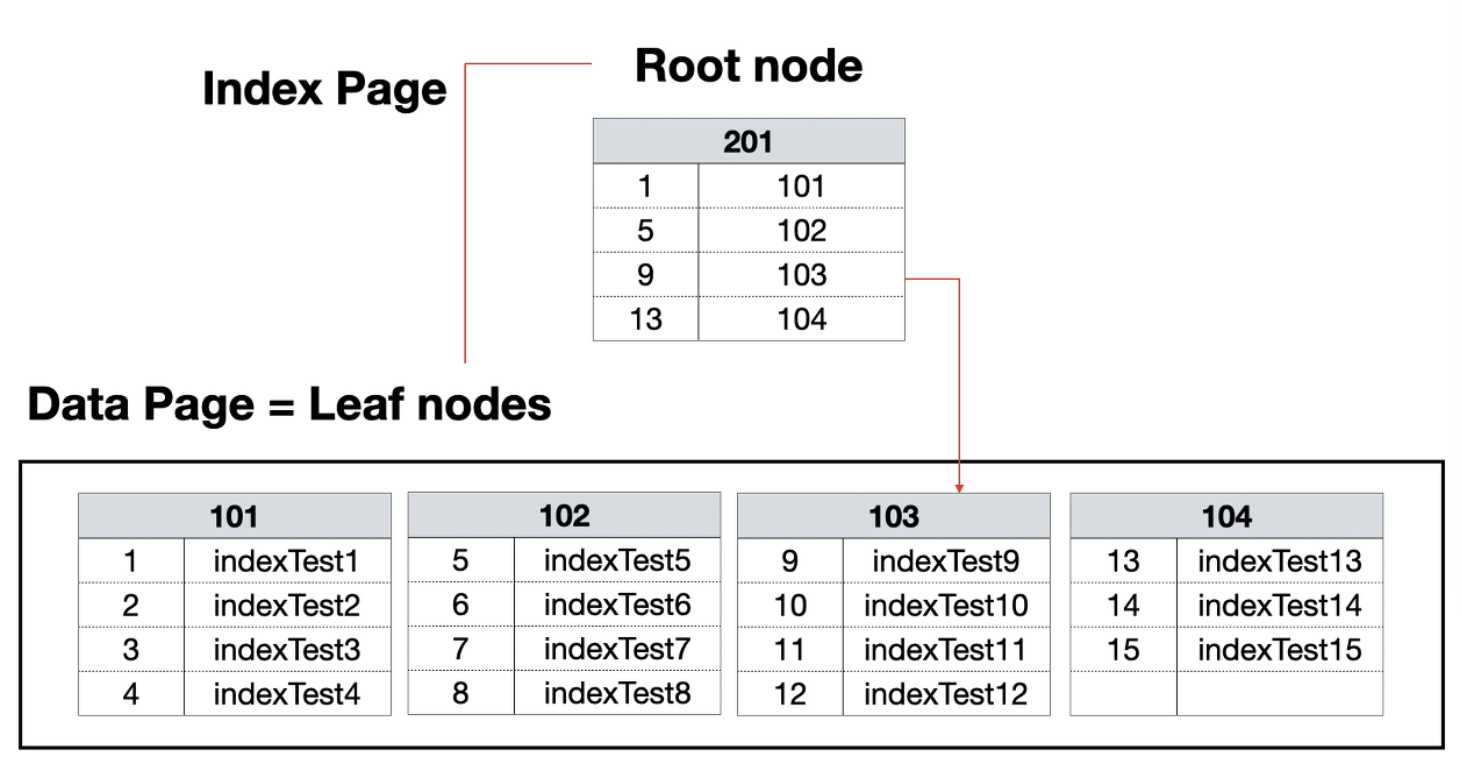
- 보조 인덱스(Secondary Index / non- Clustered Index)
보조 인덱스는 실제 데이터를 정렬하지 않고, 별도의 장소에 인덱스 페이지를 생성한다.
01-2. like문의 성능 저하 부분
내가 구현하려는 것은 [문자]를 포함한 모든 가능한 후보들을 가져오는 것이었다. 처음에 Like를 이용해 구현하려 했지만, Like 검색에서 % 의 위치에 따라 성능이 달라지게 된다.
아래 이미지는 순서대로 Like를 사용하여 '%공학%' , '%공학', '공학%' 으로 걸린 시간을 비교한 것이다. 시간은 아래 예시와 같이 mysql 프로파일링을 사용하여 테스트 하였다.
SET profiling =1;
SELECT id, name, number, abbreviation, latitude, longitude
FROM building
WHERE name LIKE '%공학%;
SHOW PROFILES;
양쪽에 % 가 있는 쿼리가 0.00127650 s로 다른 경우보다 더 수행시간이 많이 걸리는 것을 알 수 있다. 이유는 Full scan을 하기 때문이다.

이러한 Like를 사용할때의 문제점을 개선하기 위해 elastic search으로 효율적인 조회 성능을 기대하고 구축 했지만, 데이터가 많지 않은 상황에서 오히려 불필요한 리소스를 사용하는 것이라는 문제가 있었다.
02. mysql 인덱싱 외의 다른 선택지
인메모리 db를 사용하는 것이 데이터량이 많지 않은 상황에서 좋은 후보가 될 수 있다고 조언을 들어, 인메모리 db에 대해 자세히 알아보았다. redis 혹은 자바 코드상에 올려놓기를 생각했는데,
우선 자바 코드상에 올려놓는 것은 데이터 유실의 위험, 용량 문제가 있었고,
redis의 경우, 디스크 i/o가 필요하지 않아 조회시 시간이 빠르다는 장점이 있다. 반면 redis를 쓰는 경우, 잦은 수정을 한다면, redis 데이터 지속성을 위해 잦은 fork() 가 사용되어 성능이 저하된다.
기존에 mysql, redis가 구축이 되어있는 상황이였고,mysql 에서는 조회시 하드 디스크에 데이터를 저장하여 잦은 조회시 redis보다 성능이 떨어진다. 하지만,
mysql의 경우,
- key-value값을 개발자가 정하지 않고 데이터의 일관성을 유지하며 관계형으로 제공하기 때문에 후에 유지보수 하기 편할 것이라 생각
- 빌딩, 메뉴, 카테고리 세 개의 상이한 테이블의 연관관계를 한 번의 조회로 엮어 가져올 수 있는 mysql이 여러 번 조회해야하는 redis보다 유리하다고 생각
위 두 가지 이유를 근거로 이점이 있다고 생각했다.
03. mysql인덱싱와 n-gram 파서
parser 는 텍스트 데이터 인덱싱 기법이다.
parser에는 방식에는 natural language mode , boolean mode가 있는데,
natural language mode는 입력한 검색 결과에 대해 n 개의 토큰화된 단어에 대해서 해당 토큰이 하나라도 포함되는 데이터를 찾고,
boolean mode는 natural language mode에 추가 조건을 더 붙이는 방식이다.
다음
ngrinder로 테스트 한 결과를 정리하고
인터넷에 찾아보니, 이 parser방식을 mysql의 공식문서를 통해 다 뜯어본 블로그를 발견해 해당 부분을 정리해보려고 한다.
참고